DAKSH’s  3Rule of Law
Project is working to investigate the problem of pendency of cases within the
Indian judicial system through a data-driven analysis of its processes. The goal of the project is to lay
the groundwork for informed discussion, leading to the identification of sustainable solutions that will enable the judiciary to function efficiently,
dispose of cases in a timely fashion, and safeguard the rule of law. Additionally, the project hopes to
bring the litigant’s interests to the heart of the discussion on pendency,
which is necessary for any meaningful solution to emerge.
3Rule of Law
Project is working to investigate the problem of pendency of cases within the
Indian judicial system through a data-driven analysis of its processes. The goal of the project is to lay
the groundwork for informed discussion, leading to the identification of sustainable solutions that will enable the judiciary to function efficiently,
dispose of cases in a timely fashion, and safeguard the rule of law. Additionally, the project hopes to
bring the litigant’s interests to the heart of the discussion on pendency,
which is necessary for any meaningful solution to emerge.
As with all data-driven exercises, the first step was to access the data. In the case of the Rule of Law Project, accessing data proved to be a stumbling block in itself. As of September 2014, when the project started, there was no official data on the cases pending before the Indian judiciary available in a single, analysable platform. (The situation has now changed in terms of district court data with the national judicial data grid coming into existence.) Data pertaining to the number of pending cases is also difficult to ascertain accurately. The Supreme Court of India releases a court news update every quarter, where the number of cases pending in each state (before the High Court and lower judiciary of the state) is published. Some High Courts also publish annual reports which contain pendency-related statistics. However, the data from these sources are updated erratically — the most recent edition of the Supreme Court news available on its website dates September 20151 which is more than six months old.
4DAKSH
set about creating a database with details of cases pending before various tiers of the Indian judiciary
using data available in the public domain, inter alia, from cause
lists, websites of courts, and the e-courts
website. This data is then analysed to meaningfully understand the functioning of the judiciary and identify
the various reasons that contribute to the pendency crisis. Data collection commenced in December 2014, and
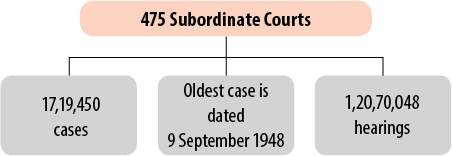
as of 1 April 2016, DAKSH has data from 21 High Courts (Fig. 1) and 475 district courts (Fig. 2) with more
than 40 lakh case records on its database, which is available for free public use on the DAKSH portal.2 The portal contains analytical tools to create
reports at an overall policy level or in granular detail at a single court to facilitate better
understanding of the data. In addition, indicative dashboards and analytics
are on display on the portal for quick glimpses into aggregate figures and the results of specific analysis
of the data. The portal also contains the Census 2011 dataset to allow for regional and specific appraisals
of the judiciary across social and economic parameters.
To analyse data collected from the High Courts, we created a process of verification of all the available material and identified the discrete data objects that were available against each case record. The cause list of every High Court is the basic repository upon which our High Court database is built. A cause list is a list of all cases that are to be heard by
FIGURE 1. DAKSH Data: High Courts
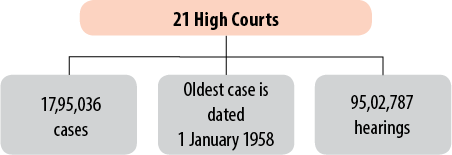
FIGURE 2. DAKSH Data: Subordinate Courts
judges on each working day in a court. It contains information pertaining to which case is heard by which judge and in which court hall. Additionally, the cause list contains the case number that indicates the case type, and the year in which a case is instituted.
The first stage of our work was to collate this data in a single, analysable platform. Our software programmes used the cause list to create a data platform that included numerous columns of information as listed by a court against a case number. The case number also contains a backstory; looking up its status on the ‘Case Status’ page, one is able to get hold of the exact date in which it entered the registry, the names of lawyers representing the plaintiffs and respondents, and if we are lucky, a record of what legal stage the case was at and the number of times it has appeared in a court. The programme was able to attach this information to the record of every case.
5The
verification for High Court data involved three stages. The first step was to look at each High Court
website and note down the data elements available against each case record.
Against this knowledge, we checked the data parsed by our software for accuracy. In cases where we knew
there was more information than our data parsers were collecting from the court websites, we were
able to fine-tune the programmes to ensure that we covered the whole ground. For example, we checked to see
if under the column for ‘Judge Name’, there is in fact only the judge’s name and not the name of a party in
the case. The second part of verification involved the comparison of data between High Courts. We
looked at whether the data maintained by each High Court was a standard set of
information. To illustrate, we checked to see if each High Court listed the same set of details against a
case number, such as date of filing, petitioners and respondents, orders passed, and the stage of the case.
Finally, the verification involved an analysis of the completeness of information maintained by each court.
Currently, most debate and discussion on pendency revolves around the total number of cases pending — somewhere around the three crore mark — across all courts in the country. Other than this monstrous figure, very little is known about the problem of delay. Our database provides more details. With our data and tools, it is possible to sort the pending cases according to case types, duration, court, court hall, and many other parameters. In the section that follows, we present various charts containing analysis of the different facets of the delay problem.3
Figure 3 shows the average number of days a case has been pending by comparing data from the 21 High Courts represented on our database. The highest average pendency is seen in the High Court of Allahabad, with a case pending for an average for a little more than three years and nine months, whereas the High Court of Sikkim has the lowest average pendency of 10 months.
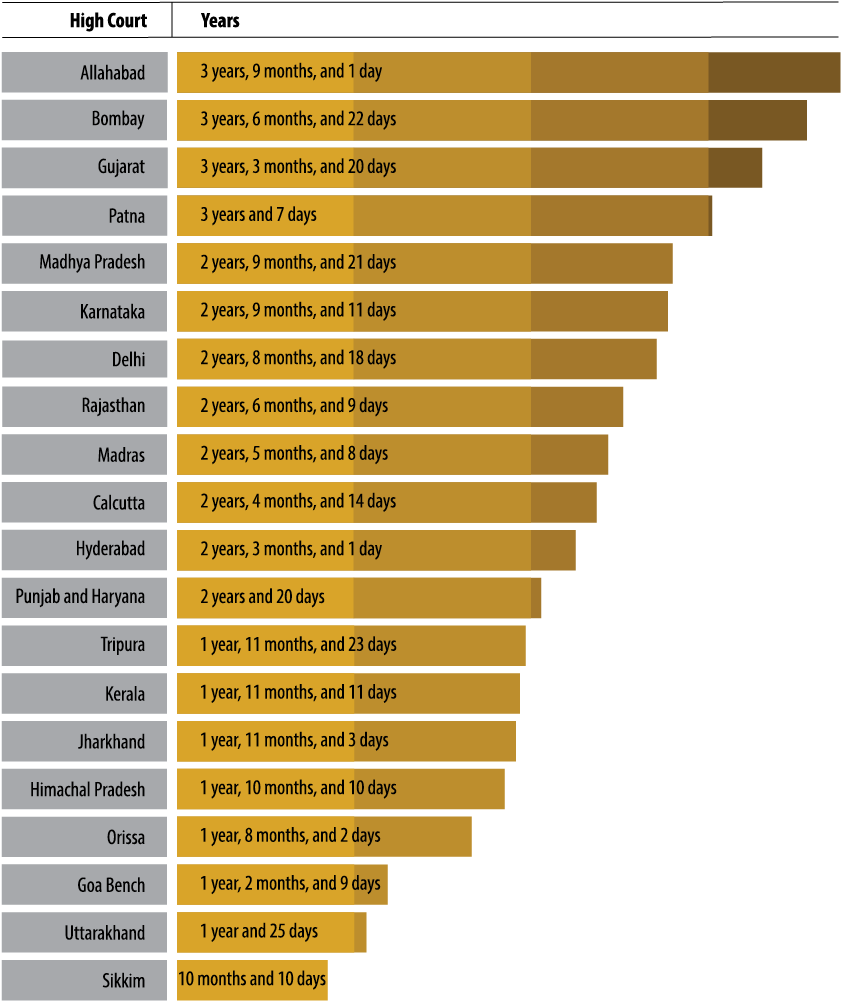
6Figure
4 shows the same statistic for the five subordinate courts with the highest
average pendency in our database.4 The
length of pendency is its most basic measure. Identifying the average length of time for which a case is
pending will allow us to understand what exactly delay means in our country and set benchmarks accordingly. It is important to remember though that we have just
taken a simple average, meaning that there are at least 50 per cent of the total number of cases pending for
longer than the average pendency!
FIGURE 4. Highest Pendency in Subordinate Courts
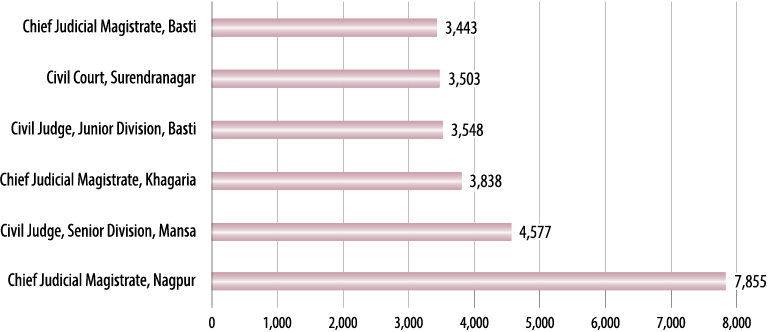
7Figure
5 offers a different view of pendency: here, cases pending in the High Courts have been categorised into
five-year brackets based on the duration of pendency. This allows us to understand the ageing of the cases
and can form the basis for prioritising hearings accordingly.
FIGURE 5. Pendency in Five-year Brackets in High Courts
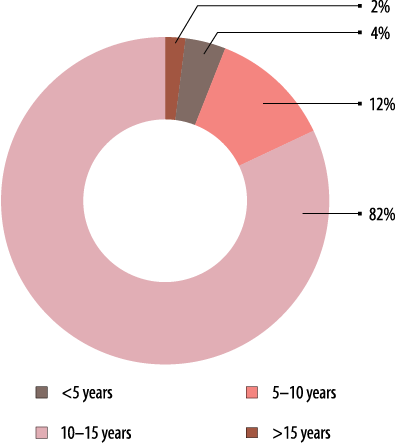
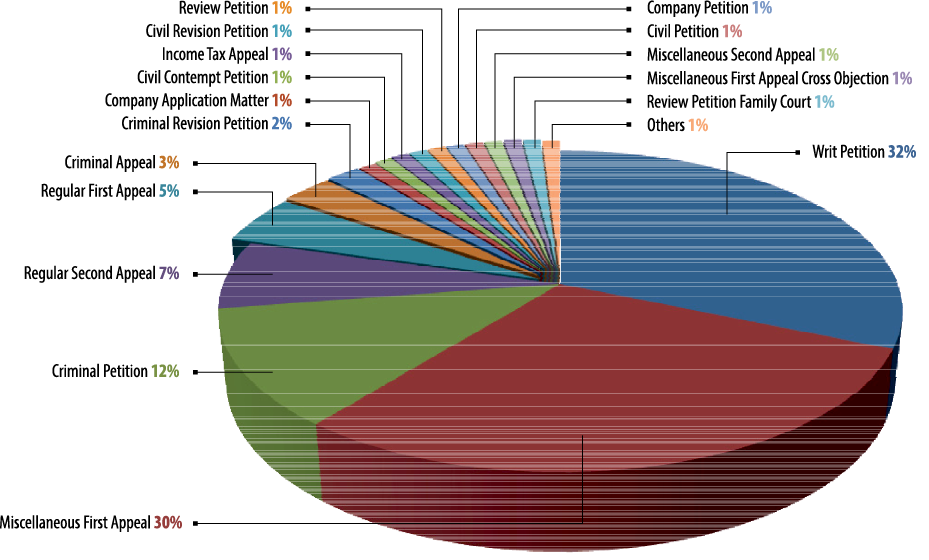
Apart from numbers of pending cases and length, a far lesser discussed and equally pressing aspect is the subject matter of the pending cases. As part of our analysis, we have categorised and divided cases pending in High Courts on the basis of their most basic distinction — civil and criminal. Figure 6 shows the proportion of civil and criminal cases in certain High Courts. Figure 7 provides an even more granular analysis in this regard, showing the types of cases in a single court, the High Court of Karnataka. The data is presented on the basis of specific case categories. For instance we can see that just two case types, Writ Petition and Miscellaneous First Appeals, constitute 60 per cent of the total workload of the court.
FIGURE 6. Proportion of Civil and Criminal Cases in High Courts
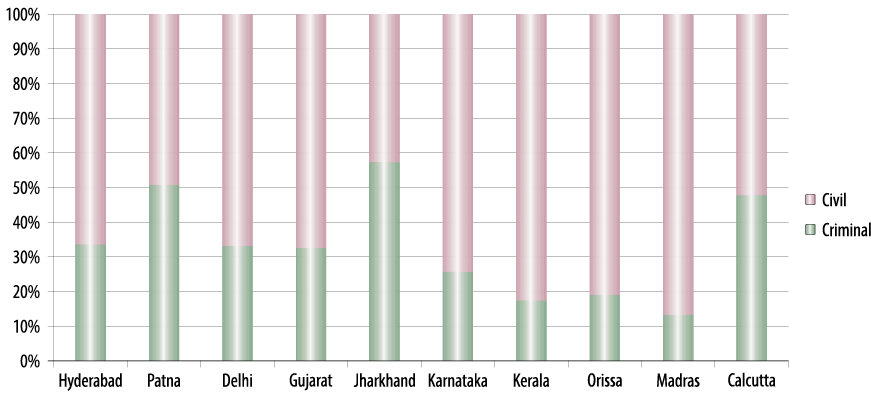
FIGURE 7. Workload at the High Court of Karnataka
8Figure
8 measures the duration of pendency of a specific case type. For example, Company Petitions, although
constituting a mere 1 per cent of the total cases in the High Court of Karnataka are pending, on average for
2,179 days, nearly six years.
FIGURE 8. Average Pendency in the High Court of Karnataka

9These
charts clearly illustrate that understanding the composition of judicial workload and overlaying it with
pendency figures is a much-needed step towards building sustainable solutions to pendency. Breaking down the
workload allows us to highlight what kinds of cases need to be focused on as well as investigate why some
kinds of cases are taking much longer than others.
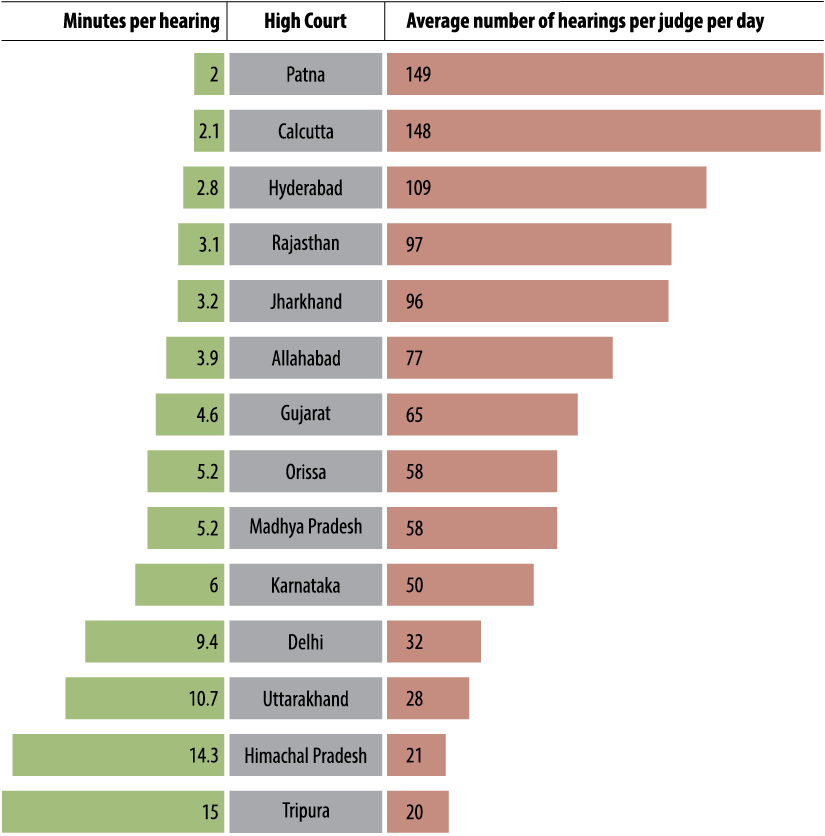
On the matter of judicial workload, a crucial point is the question
of time that each judge has during a working day. Figure 9 tells us that in the 10High Courts, judges hear
anywhere between 20 and 150 cases a day, averaging 70 hearings. Another
dimension that this chart shows is the time judges have for each hearing, which is computed based on their
working hours. This kind of analysis is key to judicial reform, as it
illustrates the severe stress that judges face each day, and shows that they need more tools to manage their
time efficiently and effectively.
Judges are not the only actors in the system who have to deal with problem of multiple hearings. Litigants and lawyers are also plagued by this difficulty. Figure 10 shows the five subordinate courts in our database with the highest number of hearings per case. The question of numerous hearings is one that needs to be dealt with swiftly, as it is a significant contributor to delay. Putting a cap on the number of hearings will allow reduction in judicial workload and may improve efficiency and also reduce the number of times litigants have to visit courts.
11Figure 10. Number of Hearings per
Case in Subordinate Courts
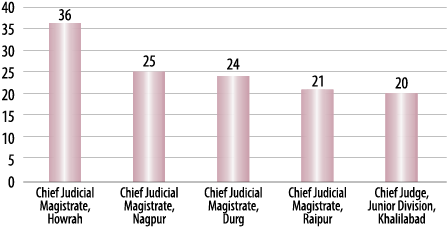
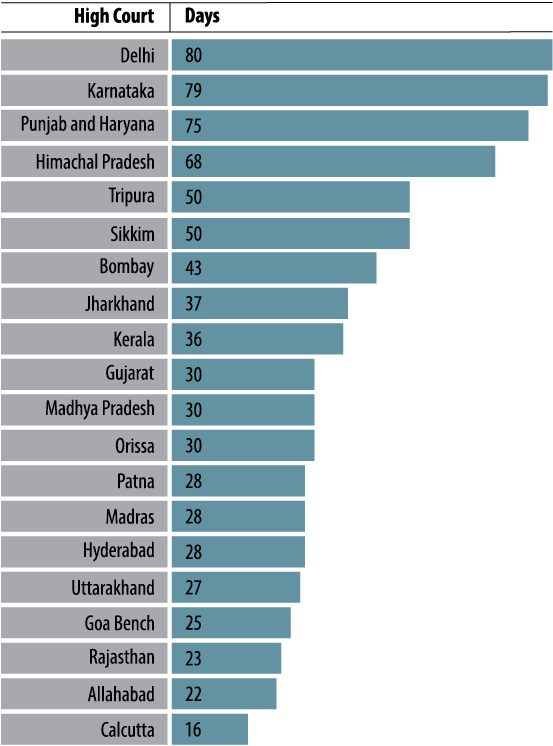
Frequency of hearings is closely linked to efficiency. Figure 11 measures the number of days between hearings in each High Court. The High Court of Calcutta holds the most frequent hearings with 16 days between hearings, whereas hearings are most far apart in the High Court of Delhi with 80 days between hearings. Figure 12 shows the same measure for the five district courts that have the highest number of days between hearings. Figure 13 also measures the frequency of hearings, but for different kinds of cases. Time spent on a case, the frequency/infrequency of hearings, and change in judicial personnel not only impact understanding of pendency, but also adversely affects the concept of fair hearing, which is a fundamental promise that the judiciary makes to the litigants.
FIGURE 11. Frequency of Hearings in High Courts
12Figure 12. Frequency of Hearings
in Subordinate Courts
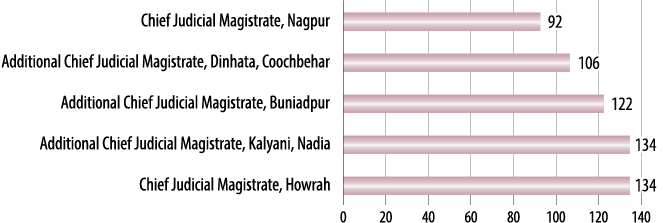
FIGURE 13. Frequency of Hearings per Case Category across 21 High Courts
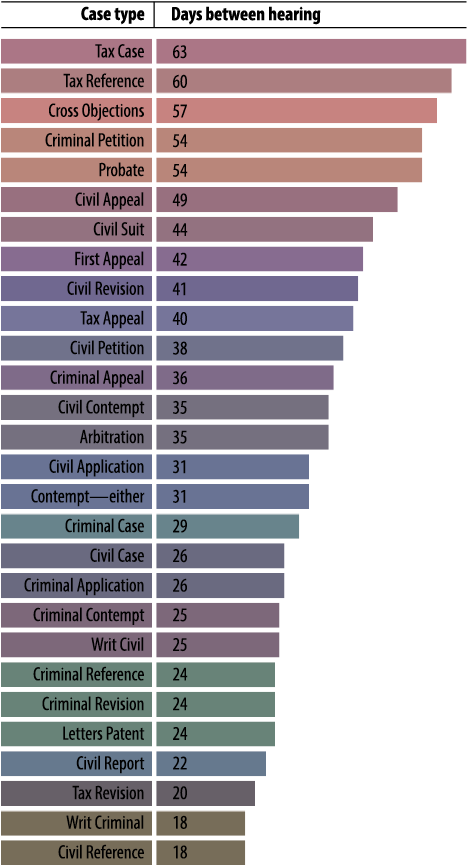
13Note: Case categories are classifications
created by DAKSH based on case types encountered across High Courts, in order to narrow down all case types
to approximately 30 categories to enable easier understanding and analysis.
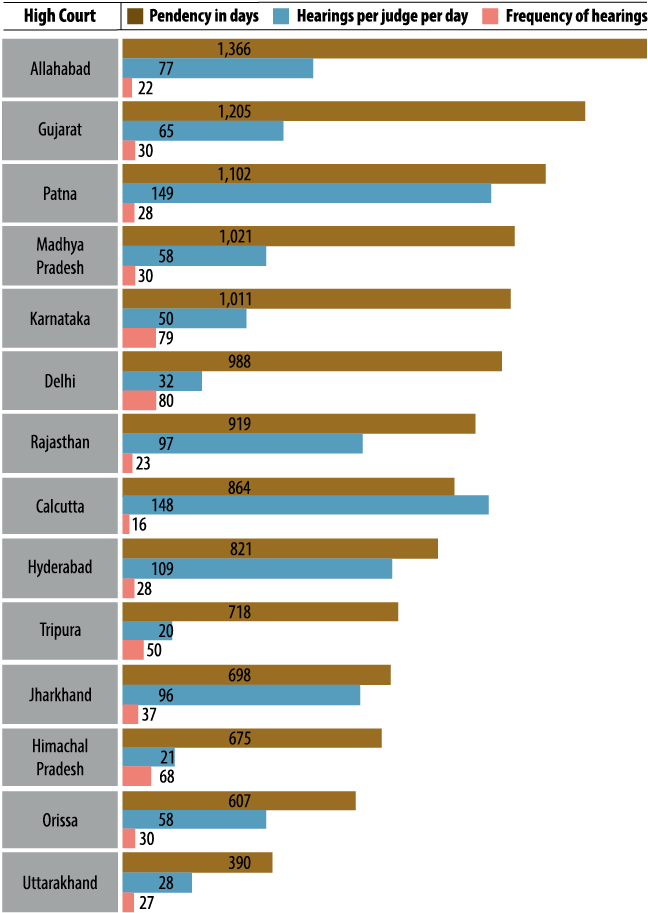
Figure 14 shows a combination of pendency, judicial workload, and hearing-related statistics. Through this correlation, we can begin to identify causal factors of pendency. For example, we measure the relationship between a high number of hearings per judge per day and length of pendency. In addition, we can study the courts that have lower average pendency and look to implement those practices in other courts.
FIGURE 14. Pendency and Judges’ Workload
Challenges
14We
faced several challenges in collection, consolidation, and analysis of data
from the High Courts and subordinate courts. They are set out in the following paragraphs. It is important
to note that the problems highlighted here are essentially from the perspective of data analysis, which will
vary significantly from that of an end-user or litigant. The data published by the courts is in all
likelihood adequate for litigants and lawyers. However, as this section will illustrate, it is not
sufficient for an understanding of pendency of cases in the system or delay in judicial processes.
Non-availability of Basic Data
The non-availability of a large set of scientific data hampers wide-ranging and meaningful analysis of pendency. This is an observation that has been noted and stressed upon multiple times by the Law Commission of India in its 245th report, ‘Arrears and Backlog: Creating Additional Judicial (wo)manpower’.5
That available data is highly varied and difficult to use is compounded by the fact that multiple pieces of basic data are not made available by High Court websites. For instance, in the first 10 High Court websites that we analysed, only five of them presented data for the field ‘Date Filed’. This field as the name suggests, contains the date on which the said case was registered in the court. Of the five courts that do not make this data available, one limits access with a captcha and the other four courts do not even have this information available. This data element is perhaps the most crucial piece of information about a case, and there is no explanation as to why it is absent in many websites. Without information on the date a case filed, pendency cannot be calculated.
Another data point that very few High Courts provide is the name of the legislation that a case is registered under, even though this information is mandatory to file a case. Without information on the legislation under which a case was filed, detailed subject-wise analysis becomes an impossibility.
One more irregular data point is the ability to track down the details of past hearings against each case, which only some courts provide. Very few courts make available a feature to see a case’s full history from the date of filing. A few courts also offer the ability to see data about disposed cases, however most do not.
Additionally, a case that originated in a subordinate court will have additional case record details — for example, a separate case number that is reclassified on entry into the High Court, and names of the court and district. These details are often unavailable.
All cases that appear in a High Court originate from a particular location within its jurisdiction. It is therefore important that the district from which the case originates is available for analysis, especially in order to create a spatial distribution of cases.
The figure in the Appendix amply demonstrates the gaps identified above. There are 64 data
elements that the High Courts make available on cases, and of these less than a third is found in all
courts. Along with current case information, there are only a few courts that provide lower court
information and links to orders. Data verification demonstrated that for each case record there was a case
type and case number, and the detail of at least one hearing (the cause list date). The cause list gives
only as much information as needed to attend a court hearing: the court hall, and the judge hearing the
matter. All other records against the case were filed away within the court registries, and their 15availability was
subject to the vagaries of clerical or administrative decisions on part of each individual High Court.
The prevention of automatic access to some case data by placing it behind a captcha is also problematic. Captchas are generally used when the system wants to verify whether the user is a human or not. As all of this case data is public it needs to be made available without preventing automated access.
The full date of filing (including the day, month, and year) is crucial to build and analyse the life cycle of cases. Availability of details of each hearing is key to understand the manner in which cases progress in the system, as well as for the identification of reasons for delay through their life cycle. Finally, the order sheets of disposed cases will provide information on what happens at each hearing, such as reasons for which an adjournment was sought. Providing access to this information would help create and understand the life cycle of a case, from the date of institution to the date of disposal, which would go a long way in benchmarking pendency. This would provide a more robust understanding of the functioning of the judicial system. However, with all the gaps in data, none of this is possible.
Quality of Information
A major challenge with using with the available High Court data is its quality. High Court data is riddled with errors that render large parts of it unusable in the current form. In order to analyse this data, it has to be thoroughly checked and cleaned up — a process that is hindered by the huge volume of data and the number of mistakes it contains. Errors contained in the data can be roughly divided into the following categories:
1. Incorrect spellings: There are an enormous number of incorrect spellings in the data. This is particularly visible in data fields such as district name, judge name, and stage name. The number of spelling mistakes is most likely due to the fact that the data is manually entered.
2. Wrongly entered information: Often we have come across data that should be under one field, mistakenly entered under another. For example, many courts have a data field known as ‘Stage’. This field indicates the current procedural status of a case. Several times we have found this information in the field reserved for information about the legislation under which a case is filed. In addition, that the information is in a wrong column is not always apparent, especially in the case of data fields that are not clearly defined such as stage name and case categories.
3. Incomplete information: In several instances the name of the judge or the statute will not be complete, thus making the case record in question irrelevant for analysis.
4. Abbreviations: Much of the data on High Court
websites is expressed in abbreviated form. These abbreviations vary widely from court to court. There is no
centralised key available to navigate through the data, which makes the data undecipherable for users
without a legal background. In addition, even those users equipped with legal knowledge have no way of
knowing whether they are interpreting data correctly. For instance, each court uses case types to categorise
and label cases. Most of these case types are in the form of abbreviations and there is no key provided for
understanding the case type list on each website. In the absence of a key, it is unfeasible for anyone other
than a local lawyer to understand the data. Without tools such as data dictionaries and keys to 16abbreviations,
amalgamation and correlation of data become impossible.
5. Specific problems: Certain data fields have problems specific to themselves. For example, many courts have a data field called ‘Case Category’ assigned to each case. In some courts, this category is used to indicate name of the statute that the case is filed under, whereas in other courts, it makes no reference to the statute and carries information on subject matter. Since this is not standard, it cannot be relied on for analysis.
One of the biggest challenges is the complete lack of data standardisation in High Court data available online. Very simply, in terms of data, every High Court is an island. Each High Court website has its own site layout, data formats, and varying extents of data availability. This lack of data standardisation is puzzling and troublesome, as logically case-related information should be uniform. To add to the problem, the variations in data are by no means minor (as exemplified by the ‘Data Availability in High Courts’ chart in the Appendix).
Further, even within each High Court’s website, the same data is at times displayed differently in different places. A good illustration of this is case type lists. Case types are categories created by High Courts to classify cases. Two different lists of case types are available on High Court websites. One can be found on the case status page of the High Court, where the pending status of current cases can be looked up. The other list of case types can be found in the cause list, which lists daily all the cases that will be heard in the High Court. The case type lists on the case status pages and the case types used in the daily cause lists are not the same. This is a perplexing difference, as we assume that at least within a court, case types would be the same.
While most websites have case status pages and cause lists, four courts, namely High Courts of Jammu and Kashmir, Manipur, Meghalaya, and Sikkim do not have case status pages. This means obtaining any current case information in these states is not possible.
While High Courts make available the type of order issued by a judge after a hearing when the case last appeared in a court hall (‘Order Type’), they are a hodgepodge of text fields that are not standardised.
The lack of standardisation in High Court data does not affect most users of the system, since their concern is focused on their own case. However, it does affect the ability to aggregate and analyse data for each High Court and across High Courts. Due to the lack of standardisation, even simple analyses of cases pending in the courts cannot be carried out, and in the absence of comparable elements, comparative analysis cannot be carried out. It also critically impedes an overall analysis of the judicial system.
Amongst the information that DAKSH collects for High Courts, ‘case type’ as a data element is key to categorising cases. This section describes the importance of case types as a piece of judicial data, the process used to categorise them, the problems of categorisation, and the need for a systemic standardisation of case types.
In a system with millions of cases, each case needs a unique identity or ‘fingerprint’ of sorts.
To create these unique identities, cases receive a special 17nomenclature from the courts known as a
combined case number. Combined case numbers are one of a kind within their High Court of origin. Combined
case numbers are made up of three parts — a case type indicated by an abbreviation, a serial number and the
year of filing.
The first component of the nomenclature of cases is a case type. In order to classify and identify cases, the courts themselves have created categories known as case types. These categories are based on varied factors, such as the subject matter of the case or the legislation a case falls under. Case types are relevant right from the first stage of the judicial process, namely, filing. When a case is brought before the registrar of the court to be filed as a case, a case type has to be chosen for it.
Given that many case types specified by the courts are long and complicated, each case type is also given an abbreviation, which is usually made up of the first letters of each of its constituent words.
Case types are created based on a number of factors, the important among which are listed as follows with examples:
1. On the basis of subject matter: Writ petitions are cases that are filed in the Supreme Court and High Courts seeking the enforcement of fundamental rights as well as other legal rights. They make up a majority of High Courts’ work and are usually filed under the case type ‘Writ Petition – W.P.’ Subject matter can be additionally combined with the stage of proceedings to create further case types. For instance a criminal appeal (usually found with the abbreviation CRL.A) is a case whose subject matter and stage of proceedings have decided its case type. As the name suggests, it is criminal in nature and is at the appeal stage.
2. On the basis of stage or nature of proceedings: An ideal example for this factor of creation are case types dealing with interlocutory applications found under case type ‘IA’, which are applications to the court for any incidental proceedings in a case that is already instituted in the court.
3. On the basis of legislation that the case falls under: Several High Courts list a case type ‘HMA’. This deals with cases under the Hindu Marriage Act, 1955. Usually, these cases involve divorce proceedings. As they are governed by a single legislation and are numerous, they have been classified as a case type of their own.
Case types are crucial pieces of data as they form the basis for most kinds of comparative analyses, both amongst and within High Courts. Once case types are categorised, they can be compared within a High Court, as well as between High Courts. Case types are essential pieces of data to benchmark delay.
A good example of case type–based analysis is Figure 8, in which the average pendency in the High Court of Karnataka is compared across case types. This kind of analysis is only possible when case data contains case type information.
It was evident that for a nation-wide analysis of pendency to be carried out across High Courts and to facilitate even rudimentary comparisons, a normalisation table for case types across High Courts would have to be created, and case types would have to be categorised. The process of categorisation that we undertook, can be broken down to four main phases.
1. 18Collection of case type lists
from High Court websites: There was no readily available official compilation of case types from all
the High Courts in India, hence this was data that had to be collected and collated. To complicate the
process, no High Court had an official list of case types available as a ready to use document. Due to the
paucity of resources and time, physically visiting each High Court to collect the case type list was
unfeasible. Thus, the case type lists were collected from the case status page of the website of each High
Court. The case status page allows a person to see details about cases that have been instituted in that
particular court. It has varied fields for searching — including party name,
judge name, and combined case number. While
searching by combined case number, to fill in the correct case number, a user has the option to choose from
a drop-down menu containing all the case types that can be filed in that court. Each High Court has such a
drop-down menu, which was copied to obtain the list of case types.
2. Choosing a base list: After the case type lists from 24 High Courts were assembled, in order to normalise them, a base list had to be chosen, to which case types could then be matched. At this juncture, the most extraordinary aspect of the categorisation exercise came to light. The sum total of all case types across the 24 High Courts amounted to an astonishing 2,553 case types. Given this huge number, it was decided that the base list should be as comprehensive as possible and it was for this reason that the list of case types from the High Court of Bombay was chosen. This was by far the longest list of case types amongst the 24 High Courts, containing 289 case types.
3. Method of case type comparison: After choosing the base list, the case type list of all other High Courts was matched to it. At this stage, the endeavour was to render as much existing variance invariant as was possible. For each High Court, all the case types that corresponded to a case type on the base list were grouped together. For example, in the High Courts of Karnataka and Delhi, case type ‘RSA’ stands for Regular Second Appeal, which corresponds to case type ‘SA’ or Second Appeal in the High Court of Bombay. Case types that could not be matched to the base list were highlighted. Once every case type list had finished a preliminary matching with the base list, a list of unmatched and unique case types was created and added to the base list.
4. Creation of final case categorisation index: The updated base list had over 380 distinct case types. The index was created as a chart, and next to each case type from base list the corresponding case type from each High Court was listed. We added two levels of filters, termed ‘category’ and ‘super category’. This was essentially a grouping of case types to enable various levels of analysis.
Further Categorisation and Super Categorisation
To create depth and add robustness to the categorisation process, we added additional levels of classification. Of the final list of 380 case types, each was placed under one of two basic classifications — civil or criminal — 12 super categories and 100 categories.
To simplify the case categorisation as much as possible, we
attempted to add a ‘civil’ or ‘criminal’ classification to every single case type. This classification looks
to partition cases on the basis 19of their most fundamental divide — the ‘male’/‘female’ equivalent for cases.
In addition to the civil or criminal classification, to add complexity, we created categories and super
categories for which we grouped case types together on the basis of subject matter and stage of proceedings.
As mentioned above, case types varied from each other in numerous ways. There was some variance that was expected; however a majority of the inconsistencies could not be explained. This section details the variance that manifested through the course of this exercise.
1. Variance in type: This is the most common variance due to the huge volume of case types. There were numerous case types that featured on a particular High Court’s list but were not found on the case type lists of other High Courts. This means there are case types that are unique to one or a few High Courts. However, realistically, these case types should be present on all lists. A good example for this type of variance would be the case type ‘Criminal Anticipatory Bail Application’, available only in the High Courts of Bombay, Guwahati, Jharkhand, and Tripura. Anticipatory bail can be granted by all High Courts, and thus the question arises as to why only four of 24 High Courts list it as a distinct case type. This is only one of many case types, which should logically be on every case type list, but in practice are missing.
2. Variance in form and description: This is the most problematic and illogical variance. Identical case types are given completely different names and abbreviations across High Courts. These case types deal with the same subject matter and there is no apparent reason as to why they have been named differently. The most striking illustration of this form of variance is the case types that identify writ petitions. Across all the High Courts there are upwards of a hundred case types with variant nomenclature and abbreviations, all pertaining to writ petitions. Table 1 shows the variance in description of criminal writs across nine High Courts.
TABLE 1. Criminal Writ Case Types in Nine High Courts
|
High Court |
Short Form |
|
Allahabad |
CRLP |
|
Bombay |
CRPIL |
|
Punjab and Haryana |
CRWP |
|
Himachal Pradesh |
CRWP |
|
Patna |
CWJC |
|
Jharkhand |
W.P.(Cr.) |
|
Delhi |
W.P.(CRL) |
|
Tripura |
W.P.(CRL) |
|
Kerala |
WPCR |
3. Variance in level of classification: The case type lists across High Courts differ hugely in their degrees of stratification. To provide an example, the High Courts of Bombay and Jharkhand both had a very comprehensive classification; however, the former list had 289 case types whereas the latter had just 59 case types. Where Bombay chose to go into great levels of granularity, Jharkhand was broader in its grouping. To illustrate, Table 2 contains a list of tax-related case types from both these High Courts.
TABLE 2. Comparison of Tax-related Case Types between the High Courts of Bombay and Jharkhand
|
High Court of Bombay |
High Court of Jharkhand |
|
1. Agricultural Income Tax Reference |
1. Tax Application |
|
2. Estate Duty Tax Application |
2. Tax Appeal |
|
3. Estate Duty Tax Reference |
3. Tax Cases |
|
4. Excess Profit Tax Reference |
|
|
5. Expenditure Tax Reference |
|
|
6. Gift Tax Appeal |
|
|
7. Gift Tax Application |
|
|
8. Gift Tax Reference |
|
|
9. Income Tax Appeal |
|
|
10. Income Tax Application |
|
|
11. Income Tax Reference |
|
|
12. Interest Tax Appeal |
|
|
13. Maharashtra Value Added Tax Appeal |
|
|
14. Sales Tax Appeal |
|
|
15. Sales Tax Applications |
|
|
16. Sales Tax Reference |
|
|
17. Super Profit Tax Applications |
|
|
18. Super Profit Tax Reference |
|
|
19. Sur Tax Appeal |
|
|
20. Sur Tax Application |
|
|
21. Sur Tax Reference |
|
|
22. Tax Appeal Civil |
|
|
23. Wealth Tax Appeal |
|
|
24. Wealth Tax Application |
|
|
25. Wealth Tax Reference |
20While neither showing great detail nor having a more generic grouping is a
clear indicator of good classification, the variance in the level of detail thwarts the possibility of
methodical comparison of courts.
4. Duality: When a case is instituted and is being filed in the High Court Registry, a case type has to be chosen for it. However, this is challenging, as there are cases that could fit easily into either of two separate case types within a single High Court’s case type list. For example, in the High Court of Andhra Pradesh, contempt appeals could fit under First Appeals as well as Contempt Cases. Which then is chosen? In essence, case types are sometimes nebulous and often overlap. There are no guidelines on choosing case types in cases of duality.
5. Variance in local flavour: This was the expected variance that was seen across High Courts. There is a clear local flavour to each list, where case types unique to each, show up. These case types are derived from major state specific legislations as well as more cultural and geographical characteristics. Good examples are the High Court of Bombay, which has numerous case types dealing with Parsi personal law, and the High Court of Kerala, which has a number of Devaswom Board related case types.
Specific Challenges during Categorisation
The difficulties that came up through the process of categorisation can be broadly summarised as follows. These challenges have prevented us from completely understanding the data and also impeded analysis.
1. 21No official list of case types: As mentioned before, no High Court has
maintained a document on its website listing the case types and abbreviations used by that particular High
Court. The lack of easily available information from an authentic source made the collection process very time consuming.
2. No centralised key or full forms available to understand case types: For several High Courts, the available written format of case types was merely a list of abbreviations. We could not find official expansions or a key to the shortened versions released by the High Courts and had to look at order sheets of individual case types to determine what the full form was. Even after this exhaustive exercise, there are still case types which cannot be understood or expanded. The High Courts of Bombay and Kerala contain a large number of such case types. The lack of centralised key resulted in categorisation being very time consuming and leaving a higher margin for ambiguity and error in expansion and thus in categorisation.
3. Difference in case type lists between case status page and cause lists: Once we started collecting data from the High Courts, it soon became obvious that the case type list available on the case status pages of the High Court websites and the case type list used in the cause list (from where DAKSH collects a majority of its data) were not the same. On several occasions, there were case types that had different names on the case status page and cause list. To illustrate, in the High Court of Delhi, there is a case type named ‘CO.APPL.(C)’. Expanded, this case type refers to a civil company application. However, on the cause list, civil company applications are given the case type name ‘CA(C)’. Another problem was that there were case types that had not appeared on the case status page (in the drop-down menu), which appeared in the cause list. For example, from the High Court of Kerala’s cause list, we found case types ‘DOC’ and ‘DPage’, however neither of these appear on the drop-down menu on the case status page of the High Court’s website. These are just two examples out of hundreds of such case types. This resulted in uncategorised and unmatched case types appearing in the database, which further left analysis incomplete. To correct this, a categorisation of case types from the cause list had to be carried out. The dichotomy of case types between the case status page and the cause lists is one for which no explanation has been found and raises questions on judicial administration — how do the Registries themselves match case types from these two separate lists? Having two different lists means that updating the categorisation table will be a hugely time-consuming task.
4. Large number of case types: The sheer volume of case types, over 2,500 of them, was the primary cause for the difficulty of the categorisation process. Given the fact that categorisation was completely manual and not automated in any way, case types had to be matched and categorised one by one.
5. Ambiguous case types: When we were adding categories and super categories (formulated by us), there were case types that could fit into multiple categories. For instance, does a criminal miscellaneous appeal fall under miscellaneous appeals or criminal appeals? Do civil revision petitions fit better under civil petitions or revision petitions? These are just two of the tens of ambiguous case types we came across.
22As
case types are lists created by the High Courts, without any definitions provided, ascertaining where the
case types would fall could not stay a very scientific and precise process. In addition, when the
‘civil’/‘criminal’ tab was added, there were numerous case types that were meant to include both civil and
criminal and thus could not be tagged as just one.
Reasons for Standardisation
While there are numerous specific reasons for case types to be standardised, they can be grouped under the following heads.
1. Systemic reform: While the lack of standardisation in case type categorisation does not affect the majority of litigants and individual players within the judicial system, it poses a mammoth challenge from the point of view of systemic reform. Without proper categorisation, how certain kinds of cases fare in courts cannot be effectively compared. Comparisons need to be made both amongst and within courts, in order to benchmark delay and to understand judicial efficiency. For instance, there are certain kinds of criminal cases that need to be resolved with more urgency than other matters, however if these criminal cases cannot be identified, it cannot be confirmed whether this is, in fact, being occurring.
2. Ease of administration: An organisational position to maintain standard case types at the High Court level would allow more transparency, ease of understanding of the judicial system, and alleviate the inconvenience of processes such as transfer of cases.
3. Poorly and loosely defined case types: The fact that case types are so nebulous, numerous, and without rigid definition give parties space for manipulation and creates disorder. There are also higher chances of cases being filed under the wrong case type, which could result in the judge asking for the case to be refiled. Case types need to be more watertight and well-defined to prevent confusion or wrong application while filing the case.
Changes in Data Management: Some Recommendations
Based on our experience with data from the High Courts and e-courts websites, we recommend a few changes, that we believe are not large-scale, but can have a large impact on the manner in which things will progress. Some of them are listed below.
Declare Case Types Publicly
Since the relevant rules are clear about case types, the case types that High Courts — and subordinate courts — use can be made public on the e-courts and High Court websites. These case types should be annotated with a description for each type, so that both the litigant and the court clerk can understand details easily.
Some data such as ‘Date Filed’, ‘Act’, ‘Section’, ‘Criminal/Civil’, ‘Case Stage’, ‘Decision Date’, ‘Order Type’, and lower court details such as ‘Current Stage’, ‘Purpose of Hearing’, ‘Whether Reached’, ‘Order Type’, ‘Parties Present’, and ‘Adjournment Requested by Party during Hearing’ should be made mandatory and available online, so litigants, administrators, and analysts can equally benefit.
Standardise Case Stages and Orders
23There are detailed rules about the stages that a cases goes through in each
court, but the software used does not reflect those rules. Data entry and later tracking will improve
significantly if case stages are standardised and selected from a list of available choices instead of being
left to the vagaries of data entry. A similar approach to order types will help make things easier for
everyone concerned.
Standardise Names of Key Individuals
Information such as litigants’ names cannot probably be standardised, but judges’ names certainly can. This step will help schedule things better for judges, given the caseload, and help the courts move cases as needed very easily.
Ensure That References to Statutes Are Coded Correctly
Where data such as applicable statutes and their sections is actually available, it is embedded in badly formatted strings. Making sure that they are available in a predictable format will ensure that judges and clerks spend a lot less time poring through unrelated files. For example, updating a list of related cases that advocates present will make sure judges can get to the related information (including judgments) quickly.
Track Transfers and Other Transactions
Only a few of the High Court websites record transfers, reclassifications, and case regroupings online. The e-courts system however does this very well — implementing a similar system in all the courts will ensure that cases can be tracked and pendency assessed in a more transparent manner.
Update Details of Order/Judgment and Party in Whose Favour It Was Made
Since precedents are very important in the legal system, litigants (and other participants including lawyers and judges) would be well served in understanding, on their own, the results of other cases that they see similarities with. Updating this information after the conclusion of a case would make the system that much more transparent and accessible.
Validate Data Before Making It Public
Right now, websites, particularly the High Court websites, include data with dates from the 12th century. This is because of errors in data entry — 2014 being entered as 1204, for example. Most court websites have made no effort, it seems, to clean the data before it is made public, leading to confusion and a general lack of trust in the website data. Basic cleaning of data before being made public will make a huge difference in the general public trusting these sites as much as they trust the court system.
———————
Notes
1. Supreme Court of India. 2015. Court News, 10(3), available online at http://supremecourtofindia.nic.in/courtnews/July,%202015-sept-2015.pdf (accessed on 5 April 2016).
2. The portal can be accessed at zynata.com/base/src/index.html#/access/signin?portal=dakshlegal.in after completing the registration process.
3. 24The data analysed in this section is as of 1 April 2016 in our database.
4. For this, and other analyses, of subordinate court data presented in this chapter, we have chosen only those subordinate courts for which we have over 1,000 cases in our database.
5. Law Commission of India. 2014. ‘Report No. 245: Arrears and Backlog: Creating Additional Judicial (wo)manpower’, available online at http://lawcommissionofindia.nic.in/reports/Report245.pdf (accessed on 15 March 2016).